Google Patent Signals That You Might Not Need LLMs
You don’t need Thor’s hammer to kill a fly.
Sign up to get cutting-edge insights and deep dives into innovation and technology trends impacting CIOs and IT leaders.
Not every task requires the full force of a large language model.
As the industry continues to build bigger and better models, Google is looking at ways to save energy: The company is seeking to patent a system for automatically mixing the usage of multiple generative models with “differing computational efficiencies.”
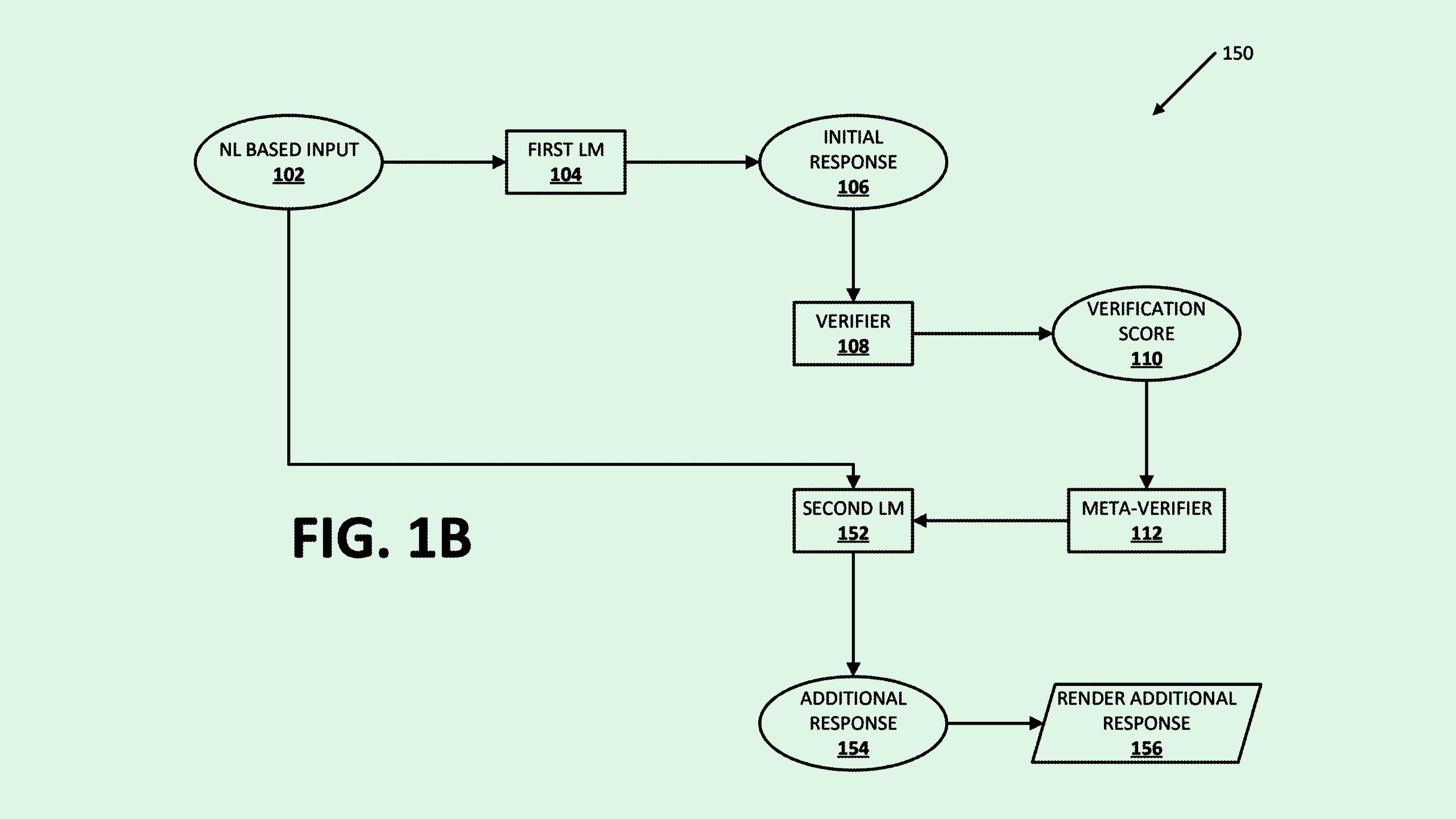
Upon receiving a query, Google’s system will first feed the input to a small, resource-efficient AI model to come up with an initial response, which is then checked by a verifier and assigned a quality score.
If the score is high enough, it’s sent back to the user without engaging a more powerful model. If not, the original input is sent to a large language model for a more in-depth, high-quality response.
The tech can lower compute costs and increase response times by using powerful language models only when necessary. “A smaller counterpart to a larger model can include 25%, 33%, 50%, 66% or other percentage less parameters than the larger model … Such a smaller-size counterpart may be sufficient for processing some content,” Google said in the filing.
Google’s filing highlights an important and ever-present question that enterprises are weighing as they continue to build AI into their businesses: How much power is too much? While the powerful AI models coming from the likes of OpenAI, Anthropic and Google are capable of complex tasks, you don’t need Thor’s hammer to kill a fly.
Google isn’t the only company interested in small models – OpenAI, Microsoft, Alibaba and more all have small model offerings. These models could become even more valuable as enterprises continue to question the value of their AI investments and seek efficiency gains in smaller packages.
Recent News
-
How OpenAI Became a C-Suite Darling

Photo by Nik via Unsplash



-
Microsoft Patents Signal Demand for Explainable AI
Photo via U.S. Patent and Trademark Office
-

Bill McDermott, CEO of ServiceNow, via ServiceNow. -
Photo via U.S. Patent and Trademark Office


-
Don’t Know Where to Start with AI? Stay Flexible.
Photo via Vanguard



