IBM Patent Keeps Users from Oversharing With AI Models
AI integrations are causing many cybersecurity teams to rethink their strategies.
Sign up to get cutting-edge insights and deep dives into innovation and technology trends impacting CIOs and IT leaders.
With AI still besieged by security issues, IBM is examining ways to keep personal data from being put into models in the first place.
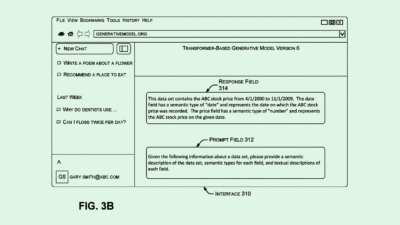
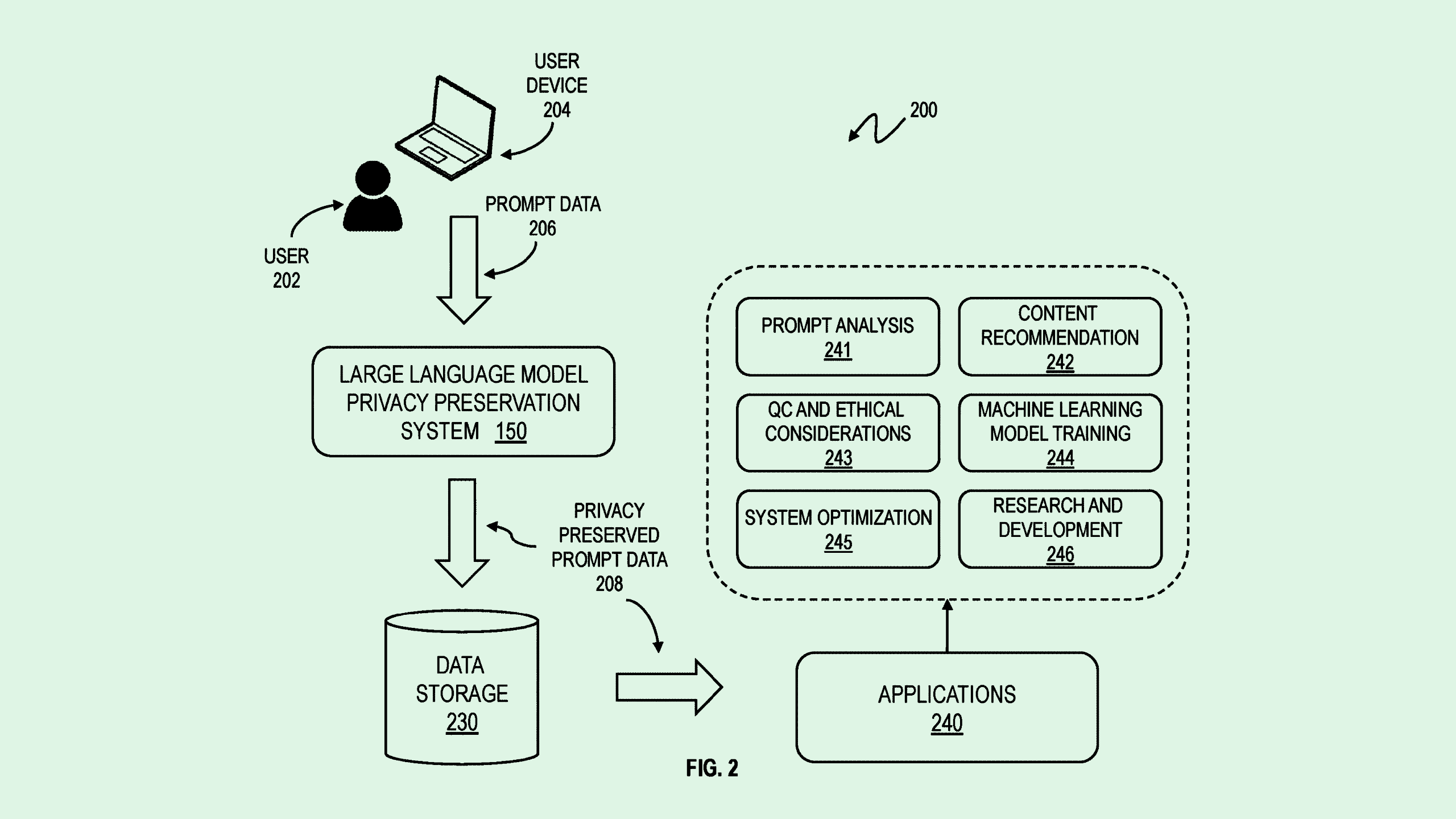
The company filed a patent application for a “large language model privacy preservation system” that would monitor prompt inputs for sensitive data, then modify them before they are processed by the model if that data is present.
“Storing the prompt data could potentially reveal sensitive information about users and reduce user trust in the large language model,” IBM said in the filing. “Existing solutions, such as data compression, encryption, federated learning, and differential privacy present tradeoffs in efficiency, accuracy, and usability.”
The system scans user inputs to generative AI models in search of personally identifiable information, like names, emails or phone numbers. Along with catching that data, the system classifies the prompt into a relevant category, helping the model understand its intent without revealing personal data.
IBM’s tech then substitutes the personalized information with generalized placeholders, and stores only the anonymized version of the user prompt for training.
Lots of companies have sought solutions for AI models’ ever-present data security risks. Microsoft previously sought to patent tech that prevents AI prompt injection attacks; Google filed a patent application for ways to anonymize large-scale datasets; and Intel wants to patent a way to verify that an AI model hasn’t been tampered with after deployment.
And AI integrations are causing many cybersecurity teams to rethink their strategies: A report released Monday from Bedrock Security found that nine in 10 cybersecurity professionals reported evolving job responsibilities in the past year, largely relating to AI and data governance.
The problem, however, is that the speed to AI development is rapidly outpacing the ability to monitor and fix its security issues. With this rapid uptick, the onus for AI governance and data security best practices has largely fallen on the enterprises that use them, rather than the model developers themselves.
A patent like IBM’s could prevent data missteps at organizations that are still figuring out where AI governance and education fits in, catching private information before it makes its way into a model at all.
Recent News

-

Photo via U.S. Patent and Trademark Office



-
Photo via U.S. Patent and Trademark Office